EC-AGXOrin 边缘计算主机
采用 NVIDIA Jetson AGX Orin(64 GB)模组,算力可达 275 TOPS,支持多种 AI 大模型和深度学习框架。支持 22 路 1080P 视频解码、16 路 1080P 视频编码。配置工业级全铝合金外壳 + 两个散热风扇设计,7×24 小时稳定运行。广泛适用于边缘计算、机器人、大模型本地化、智慧城市、智慧医疗、智慧工业等行业领域

搭载 NVIDIA Jetson AGX Orin
搭载 NVIDIA Jetson AGX Orin(64 GB)模组,配备 12 核 CPU 与基于 NVIDIA Ampere 架构的 2048 核 GPU(含 64 个 Tensor Core),能够运行多个并发的 AI 应用程序管道,可提供高推理性能,为边缘 AI 计算、智能机器人等场景提供强劲算力支撑

主流 AI 大模型私有化部署
支持主流 AI 大模型私有化部署,如 ROS 机器人模型、Transformer 架构下大模型的 Gemma 系列、ChatGLM 系列、Qwen 系列、Phi 系列等大语言模型,EfficientVIT、NanoOWL、NanoSAM、SAM、TAM 等视觉大模型,以及 Flux、Stable Diffusion 系列的图像生成模型

支持多种深度学习框架
支持 Ollama 本地大模型部署框架、ComfyUI AI 绘画工作流框架,以及由 cuDNN 加速的 PaddlePaddle、PyTorch、TensorFlow、MATLAB、MxNet、Keras 等深度学习框架;同时支持自定义算子开发、Docker 容器化管理技术

AI 软件堆栈和生态系统
借助全面的 AI 软件堆栈和生态系统,在边缘生成式 AI 以及 NVIDIA Metropolis 和 Isaac 平台的支持下,使边缘 AI 和机器人开发实现大众化。借助 NVIDIA JetPack、Isaac ROS 和参考 AI 工作流程,无需依赖昂贵的内部 AI 资源,体验 AI 应用的端到端加速,将先进的技术集成到产品中

高带宽 LPDDR5 内存
相比 LPDDR4 实现了更大的内存容量、更高的带宽、 更快的数据传输速率、更低的功耗、更先进的错误纠正码(ECC)技术, 可以满足大模型私有化部署对内存空间和响应速度的需求, 充分发挥硬件的协同作用,使得模型能够更高效地运行, 提升整体系统的性能和能效比

多路视频 AI 处理性能
最高可支持 22 路 1080P@30fps 或 1 路 8K@30fps 视频解码,16 路 1080P@30fps 或 2 路 4K@60fps 视频编码,视频处理能力强劲,满足各类 AI 应用场景的需求

强大的网络通讯能力
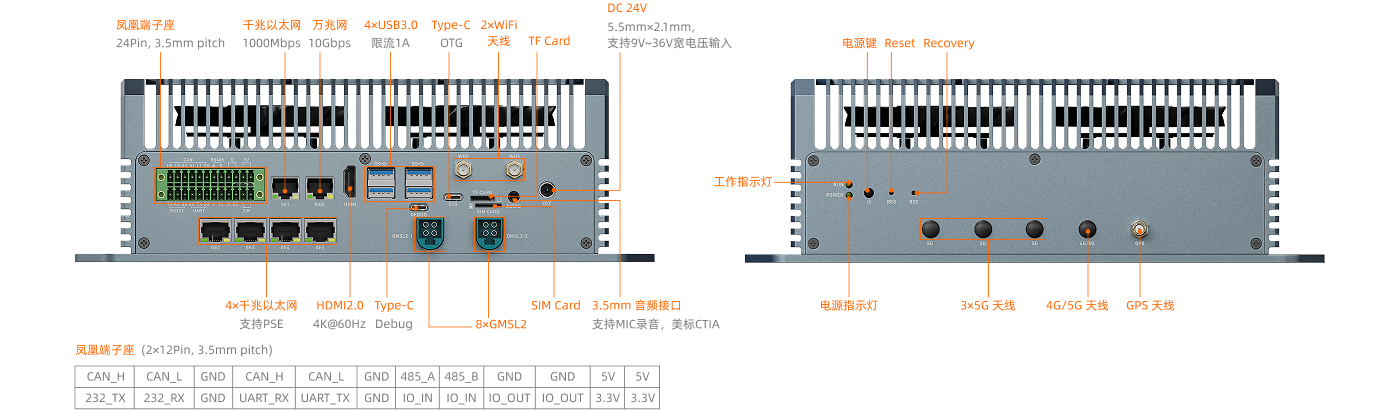
配备 1 路万兆网、5 路千兆以太网、GPS 模块,同时支持双频 WiFi 6、5G、4G 功能扩展,满足多场景网络连接需求

丰富的扩展接口
拥有 GMSL2、HDMI、USB3.0、RS485、RS232、CAN、Type-C、IO 输入、IO 输出等接口,方便连接各类外设